
GPT协助海外用户舆情分析实例
内容转载自:群核科技用户体验设计
在全球化市场中,用户的声音往往是产品和服务优化的重要指引。对于以家居设计和3D渲染技术为核心的Coohom来说,海外客户的反馈更是理解多元化需求、提升用户体验的关键。然而,面对来自不同文化、语言背景的海量评论,如何高效地进行调研和分析,成为了Coohom面临的重要挑战。
幸运的是,像ChatGPT这样的人工智能工具,凭借其强大的自然语言处理能力,能够帮助团队快速定性解析评论内容,提炼出核心洞察,为产品优化和市场拓展提供数据支持和战略参考。这项技术不仅提升了调研效率,更为Coohom的全球化发展注入了创新动力。
一、如何获取海外用户评论 – SaaS平台评论的获取
国外主流的SaaS平台软件测评主要有四个:G2, Capterra, Trustpilot, Software Advice。在这些基础上,还有一些社交媒体中的评论可以浏览,如Facebook,Youtube评论,Reddit,Instagram等。
然而,就信息量而言,社交媒体上的信息有的时候只是随意抒发的言论,存在信息量少,信息嘈杂的特点。因此,如果想要系统的爬取分析,最好从上述提到的四个专业网站上进行获取。
这几个网站,通常会要求用户对对应软件进行评分,对软件撰写长评,并且对软件的优缺点进行分析。因此,查找这些网站的数据时,不但可以获取评论,还可以收集多名用户对于软件的评分,获取多维度的分析。
在本次对于Coohom海外用户评论的调研中,笔者对Trustpilot和Software Advice两个网站的评论内容进行了爬取和分析,运用了Octparse这款非代码用户友好的软件。之所以选择这两个网站,是因为G2与Capterra有反爬虫机制,运用Octparse无法从上面提取内容。因此,只爬取了上述两个网站。
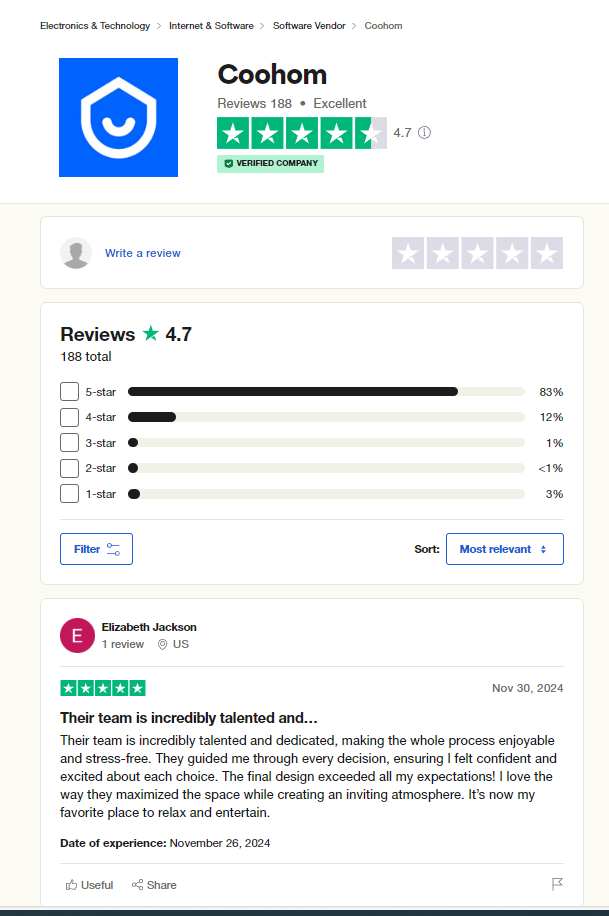

*Trustpolite – Coohom评分和评论
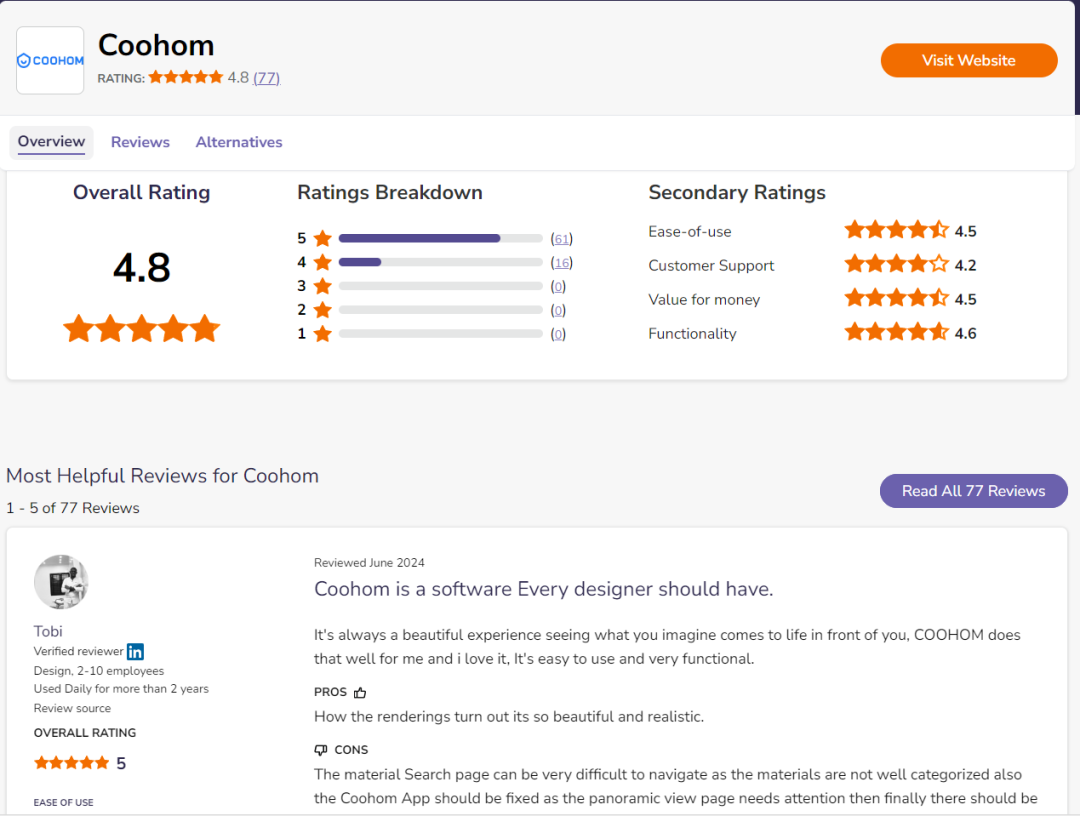
*Software Advice – Coohom评分,评论,和优缺点分析
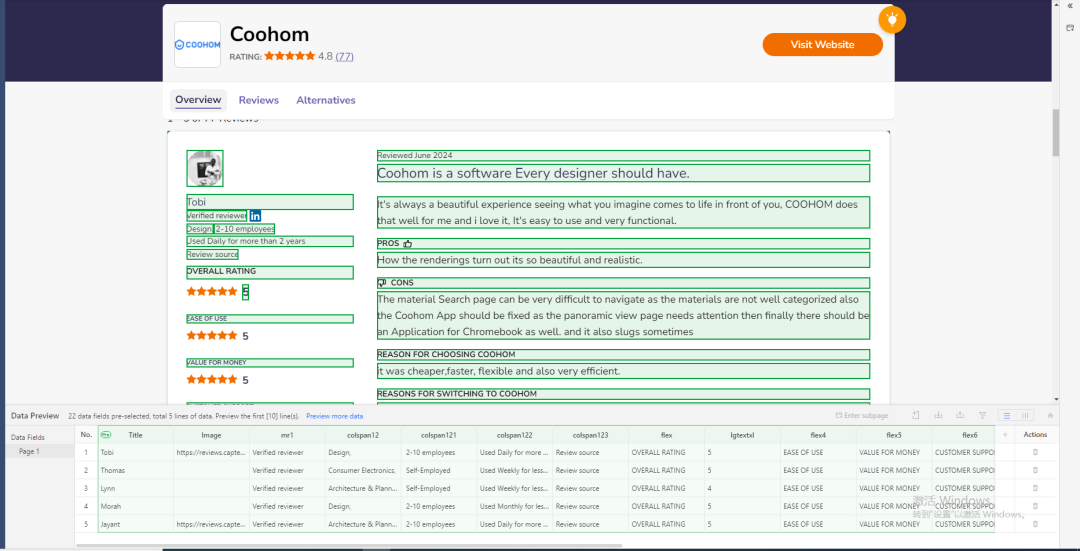
*Octparse – 网站评论爬取界面
Octparse爬取输出的内容,为包含用户信息,评论时间点,评论网址,评论内容等的excel表格。爬取时,由于代码的重复获取的因素,会有大量的depulicated评论。对于这部分评论的处理方式有两种:
- Octparse有自动去重复评论的机制,因此可以要求其自动去除。
- 但在自动去除时,有些评论可能会识别错误或者读取不灵,所以请务必浏览一下。可以将Octparse提取出来的评论部分单独复制进一个新的excel表格中,灵活运用excel的内置功能查找重复项,然后进行处理。
与此同时,还有一点需要注意,由于海外文化对于隐私保护及其敏感,因此,最好将原文件的评论部分单独复制出来进一个新的excel文件,再进行分析。与此同时,源文件的其他内容,最好销毁,至少也是进行加密处理,以防隐私泄露。在处理数据时,尤其是海外数据,保护隐私这一习惯应当作为肌肉记忆来进行培养。
第一部分操作的产物,应当为一个或者几个excel表格 – 每个表格包含且只包含了对应网站上爬取的评论内容。
二、评论的初步分析 – 利用ChatGPT进行主题获取
在第一步评论获取和去重完成之后,笔者获得了387条有效评论。但该评论只是评论源文本,还未进行主题分类。这个时候第一步,是需要运用ChatGPT对原文本进行主题的粗提取。

*GPT现有的模型
图示为GPT现有的3个模型:4o,o1和o1-mini。就这次分析的经验来说,4o宛若一个智障,不但要多次返工还会瞎编,所以在不建议作为主力分析模型使用。o1和o1-mini的文字归纳和推理能力尚可,因此可以在进行评论主题分类的时候使用。
这两者中,o1和o1-mini推理能力有所差别 – 就如名字所指示的那样,o1-mini在长文本推理和归纳方面是o1的阉割版,并且文本处理条数也受限,因此,如果需要处理长评或者复杂文本,o1是首选,其次o1-mini。除非在实在没有办法的情况下,不要用4o,如果不得已要用,请务必校准其输出结果。
但是考虑到大模型的资源受限(笔者的GPT账号是个人会员版),其中o1以及o1-mini都是有限次数使用,因此,需要将4o,o1-mini和o1搭配着使用,其中o1在核心推理步骤才使用,其余时间都是使用4o和o1-mini。至于什么是核心推理步骤,下面会详细说明。当然,如果后续人使用的是富裕的pro版,那就无脑o1,因为推理性能最好。
源数据到手,就是387条乱序评论。这时候需要进行主题的初步框定。笔者尝试过将387条评论一次性输入进GPT(o1模型)中进行分析,但是得到的结果是:文本量过大,无法处理。因此,只能采取分批次处理策略,一次性输入20-30条,然后对这些评论进行主题分析,归纳出对应主题;然后再次输入下20-30条,填充进现有主题,或者增添新主题,直到所有评论按批次处理完毕。
在前期主题提取的过程中使用的模式是o1 – 因为需要从无到有的创造主题,因此对于模型的推理能力要求更高;但是,当笔者发现主题饱和出现之后,果断将模型切换为o1-mini – 因为这种情况下对于文字推理的能力要求出现降低,只需要在现有的主题框架下填充评论即可。
但是,由于o1-mini本身的推理能力限制,在该模型进行推理完输出评论后,务必人工校准一下,因为mini偶尔会出现主题归纳不规范的情况。这时候,需要手动校准 – 错误概率不是很多,可能每40-50条评论,或者模棱两可的评论会出现这样的情况。
在主题提取的过程中,笔者从领导那里获取了一个框架:需要区分正/负面评论。那在该大框架下,笔者又手动调校了一个二级框架,设定为:
正面评论(P)
主题一
主题二
主题…
负面评论(N)
主题一
主题二
主题…
在完成这一步之后,接下来是训练人工智能。首先,就像笔者刚才所说的那样,非关键步骤不要使用o1,因此,在这步,先使用4o – 开启GPT一个新主题,第一个prompt,开始介绍背景:”我现在需要给Coohom这一设计工具进行用户评论的定性分析。接下来,我会给你输入一个框架,你理解一下输出给我你的理解。如果和我要求的一致,我会给你输入新的指令。”
这时候,GPT应该给你一个继续指令的回复。下一步,就是将框架输入给它,然后看它的理解。我输入给它框架后,它的答复如下:

很幸运,它的回答基本与我想要的一致。那我现在告诉它:我现在会给你输入评论,以20条为单位。这样子,它会回答你准备开始接收。这个时候,就做好了AI定性分析环境的搭建。
这个时候开始主题分析。在这种情况下,需要将模型切换为o1,因为要开始复杂文字推理 – 进行主题提取和创建。于此同时,在复制评论的过程中也有一个小细节 – 从excel中直接复制过去的评论,是不带句首序列点的。因此,GPT带读取的过程中,可能会出现语句混淆,然后影响分析精度。
因此,excel中复制评论过来,需要新开一个word处理一下,对每条评论进行手动标序,并且人工校准。这样,GPT读取的评论才是精准的,可以用来主题分析。

*未手动标号,直接从excel中复制粘贴的评论,会使得GPT的文本分析进行混淆
因此,在将20条评论进行手动标号之后,我会先给它做一点准备工作 – 将模型切换为4o, 输入这20条评论,然后跟他同步:“这是我要你分析的评论,你先记住,我稍后会给你指令”。等它形成记忆之后,再切换为o1,输入指令:”参考我最开始教会给你的框架,首先区分正面和负面评论,输出结果我们对齐。“当结果输出被分类为正面评论和负面评论后,再次使用o1输入指令:”在你之前分析的基础上,我需要在正面评论(P-category)和负面评论(N-category)下对评论进行子主题的提取。你分析这些评论,提取主题,然后将对应评论放在相应的主题下。不要分析单个词语,要分析完整的句子上下文,然后打印这些完整的句子在主题下。“
这一步其实有三个要点:
- 与GPT对齐评论是为了使得它形成记忆,方便后续分析进行提取。
- 分步式的输入指令:虽然我说o1推理能力相对较强,但是如果它在同一步的指令过多,它也会智障化,不是瞎编就是漏掉这个漏掉那个,徒增工作量。因此分步式的操作有利于提高精度。并且,当分步式的分析流程形成后,也可以push GPT打包这一部分操作过程,使得它形成AI版的定性分析SOP,后续只需对SOP包中的prompt进行微调即可。
- 如果不加下划线那个要求,它默认会根据单个词语或者词组的意思进行主题分类,这与人工分析中读取上下文的分析习惯不符,也容易造成错误。因此,这一部分指令要添加。

*GPT o1模型根据评论所形成的主题
当前一步完成之后,GPT中就应该有了由20条评论形成的粗主题框架。在进行下一步操作之前,可以将之前分步式操作形成的SOP创建一下。可以要求GPT:我刚才给你展示的一个工作流程。接下来,我会再次给你输入20条评论,你按照上面教你的方法,先对评论进行P/N categories 的分类,然后在把对应category下的评论放置在子评论的范围内;如果出现新主题,创建新主题并放置评论。我要求你输出P/N category下创建的主题,然后每条主题下打印出详细的评论内容,并且index回原输入的评论批次,标明是评论中的第几条。如果你学会了,回答yes.
这么创建prompt有两个原因:
- push GPT形成工作记忆SOP,之后就可以直接扔给它评论输出结果
- 要求它打印出详细的答案,适合分析完之后直接校验。在定性分析时,AI对于上下文的读取未必与我们理解的相同,故务必校验,且GPT会瞎编,要小心。

*教会GPT新的工作流程后的产物
在用这流程的prompt进行每20条多轮迭代之后,穷尽所有评论,GPT应该会给你一组所有评论归纳出来,由P/N category分类后的主题。这时候,需要将主题copy进一个word文档中再进行微调,因为有的时候GPT给你的主题可能没有按照业务想要的逻辑进行拆分,那样其实在针对性上会出现问题。这个时候,就需要与业务或者领导进行沟通,共同协助进行主题拆分。在本次调研中,拆分后的主题如下:
正面评价主题
- 渲染质量与速度:提供高质量渲染效果,速度快,满足高效设计需求。
- 用户友好性与易用性:界面直观、操作简单,适合新手和专业用户,学习成本低。
- 素材与模型库:提供丰富的3D模型和素材库,支持定制与更新,节省设计时间。
- 工具功能丰富:提供多样化设计工具,支持复杂建模和自定义设计需求。
- 模板丰富:提供多种设计模板,简化创意设计流程,助力高效设计。
- 设计与创意支持:支持创新设计,提供可视化和优化设计呈现效果的功能。
- 价格与价值:提供高性价比的功能与订阅选项,满足个人与小型企业需求。
- 客户支持与服务:良好的客户服务与支持
负面评价主题
- 价格与订阅策略问题:价格较高,订阅续费机制不透明,部分功能需额外收费。
- 素材与模型库问题:模型和素材不足,缺乏更新,导入导出兼容性差。
- 界面复杂:用户界面设计不合理,操作不直观,难以快速上手。
- 功能复杂:功能设置繁琐,工具间过渡不流畅,操作步骤过多。
- 渲染速度慢:渲染时间过长,影响设计效率,尤其是在高分辨率或复杂项目中。
- 渲染效果失真:渲染结果与预期不符,出现色差、光影效果不自然等问题。
- 技术与性能问题:软件运行缓慢、卡顿,渲染时出现延迟或错误,影响用户体验。
- 客户支持与服务问题:客服响应慢,问题解决不及时,缺乏详细操作指导和帮助资源。
在GPT的原版分析中,P category下“工具功能丰富”和“模板丰富”原本隶属于一个主题下。但是领导根据对于业务的洞察力,要求笔者分为了两个维度。同时,N category下的“界面复杂”和“功能复杂”原本也是同一个主题,同样按照相同的逻辑进行了拆分。再进行主题微调并于领导沟通过之后,就可以开始最后一轮的定性分析,评论solidate了。
三、最后一轮定性分析
这一部分的起手势,是先将模型调成4o,然后将方才调整过的主题输入GPT:这是一组主题框架,你先记住,我稍后输入指令。当4o回答记住之后,将模型调整为o1,输入指令:我接下来会给你20条评论,你根据整句上下文,将相应评论放置在对应主题下。打印出每个主题下的详细评论内容,以及每个主题的频数,以及P/N category的总频数。将详细内容打印给我,我需要校对。然后输入标好号的评论,GPT输出结果将如下:

每20条评论校对完毕之后,建议创建一个word文档保存输出结果,因为GPT能力有限,当上下文过多,特别是在300多条评论的情况下,其上下文索引会出错。因此,分阶段保存,是预防这个风险的方法。后续如果需要统计频数和百分比,手动计算即可。
当评论在新的主题下分类完毕之后,操作者应该就有了一个统计性文件:定性主题以及每个主题下的所有评论,以及相应的频数。这个时候稍作整理,创建一个excel表格,可以将相关内容全部整理在上面。
四、精选评论
当每个主题下的评论全部整理完毕时,这个时候可以要求GPT进行评论的精选。对于频数多的主题,可以精选10条; 频数少的,可以精选五条或者更少。为了达到此步骤的目的,需要先切换模型为4o,输入prompt: 我接下来要给你输入一组评论,你先记住,我稍后会告诉你怎么操作。
然后,将模型切换为o1,输入:从刚才的评论中精选出信息量最大的10条(信息量大的定义为评论者不但说出了渲染好,还说出了原因),每条索引到原评论的序号,然后打印出评论内容,选取原因和中文翻译。这样的prompt输出的内容便于人工校准,如果不满意,还可以另换。如果某个主题下评论内容过多(大于150条)GPT算力不够的话,可以分批次处理精选,再优中选优,最后达到目标。GPT的输出效果如下:

当所有主题的评论都跑完毕的时候,就可以输出整体文件内容啦!
五、定性分析中写GPT prompt的技巧
- 避免一次性输入过多内容,分批次处理校准
- prompt的内容精确,标准化,比如规定处理要素和输出内容等(避免只处理词组,输出完整内容)
- prompt忌一次性输入太多要求,可以分步式要求GPT处理,确认其学会后,打包为SOP为下面分析做准备。
- 重要分析步骤记得备份,当GPT涉及的上下文过多时,其可能会混淆。
以上
本文地址:http://sunnao.cn/archives/785
以上内容源自互联网,由运营助手整理汇总,其目的在于收集传播生活技巧,行业技能,本网站不对其真实性、可靠性承担任何法律责任。如发现本站文章存在版权问题,烦请提供版权疑问、侵权链接、联系方式等信息发邮件至candieraddenipc92@gmail.com,我们将及时处理。
相关推荐
-
AI导购爱“答非所问”,淘天京东抖音为啥还抢着做?
内容转载自:新识研究所 今年双12年终促销,既有AI数字人24小时不间断卖货,又有AI智能化推广营销工具,实时监控投流数据,批量调优自动托管,还有商家智能生成图文、视频、一键上架商…
-
怎么通过抖音放大自己的生意,获取更多客户?
内容转载自:老陈的深度思考 一、现在传统生意越来越难做,线下生意越来越难做 而那些网红,带货的却不受影响。 并且现在的流量越来越集中在几个大的平台,比如小红书和抖音。 在线下生意越…
-
“微信送礼”重燃战火,电商格局迎来新变数?
内容转载自:新播场 临近春节之际,微信放了个大招。 近日,微信小店推出“送礼物”功能,允许好友之间互送在平台内购买的商品。 今年以来,随着视频号小店升级为微信小店、深入融入微信生态…
-
滴滴“臭车”谁之过?
内容转载自:互联网那些事 近日,滴滴因“臭车”问题冲上热搜,相关的媒体报道与话题帖下面,已被大量“感同身受”的网友攻占,堪称互联网奇观! 乘客乘坐体验不满意,提供出行服务的滴滴,成…
-
服务数字化 – 成本控制塔如何构建
内容转载自:杨峻 在整个售后服务管理中,我们要想优化,必须首先做到可视化。我之前介绍的工单、备件、结算和退换货四个生命周期可视,偏重于细节和流程可视;但针对于高层管理者需要实现全局…
-
2024年最惨创业赛道,近20万家门店“无一生还”
内容转载自:螺旋实验室 当美团“附近店铺”再也搜不到蜜雪冰城、喜茶和Coco,熟悉的商圈也不见一点点的踪影时,赵晓才意识到记忆里的奶茶店已经慢慢从身边消失。 一如曾经五颜六色的冲泡…
-
需求的全生命周期的管理
内容转载自:苏逸轩 可以将需求分析分为两个阶段:前半段的核心是分析需求的真实性和验证需求解决方案(产品)的可行性,包含需求收集、需求分析、方案验证三个阶段;后半段核心则是系统思考产…
-
零售业的AI变革:机遇与平衡
内容转载自:庄帅 近年来,AI成为零售企业不可或缺的能力,智能化也已渗透至零售行业的全链路。 这并不是新业态带来的短暂性消费的新鲜感,也不是单纯追求技术赋能带来短期内的业绩提振,而…
-
扬州毛绒厂老板的转型烦恼
内容转载自:窄播 如果在小红书搜索「亭龙玩具城」,你会获得不止一篇深度攻略,涵盖商城中的热门商家和热门产品。在一些笔记里,有小红书博主晒出了自己在五亭龙暴逛3小时的战利品,那是十多…
-
90% 的老板不知道,应该怎样做短视频以及老板IP
内容转载自:老陈的深度思考 01 当你让别人喜欢你的时候,你卖什么都可以。 不要局限在一个所谓的垂类里边、不要局限于你这个行业。 当你是一个ip,有个人品牌的时候,你就不是一个售货…