
数据分析误区系列(二):数据揭示的谎言
内容转载自:佑佑和博博~
叮叮当叮叮当铃儿响叮当… 圣诞节来临,公司旗下销售同种类型礼品直播间销售数据如下:
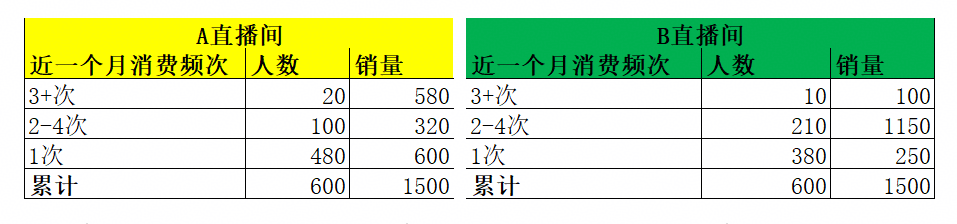

仅从人数与单量考量,A、B两个直播间的人均销量均为1500÷600 = 2.5件。那么,我们是否就能判定这两个直播间经营水平相当、不存在差异呢?答案显然是否定的。
我们能够清晰地发现,A地区的高频客户(近一个月消费3次及以上)在人数方面要远胜B地区,这一优势不仅体现在购买人数上,还体现在人均购买数量上。而且,A地区的拉新数据(480)也明显优于B地区(380);不过,在中频用户方面,B直播间则占据着显著的优势。
基于不同层级客群消费情况的对比,运营团队的同学们后续会针对这两个直播间制定具有针对性的运营策略。从这个案例当中,我们也获得了一个启示:在进行对比时,不能仅仅由于两者的平均值相近,就贸然得出两者运营状况相近的结论,而是要展开进一步的具体分析。
其实在现实生活中我们经常会掉进一个陷阱,那就是误解或误用数据。那么如何避免误区呢?一种方法是通过学习“安斯库姆四重奏”,一种由英国统计师弗朗西斯·安斯库姆创造的,表面上完全不同但有着相同统计特性的四组数据集。这些数据集揭示了我们在处理数据时候的一些常见误区。本文将从实际案例中阐述这些误区并解释如何规避它们。
“安斯库姆四重奏”指的是四组两个变量的数据集,这四组数据的统计性质几乎完全相同,例如都具有相同的平均值、方差和相关性等。然而,当我们绘制出这四组数据的散点图时,我们可以清楚地看到,每组数据的分布形状完全不同;其中一组是线性关系,第二组是曲线关系,第三组是由一个离群值引起的线性关系,以及最后一组是完全随机的关系。
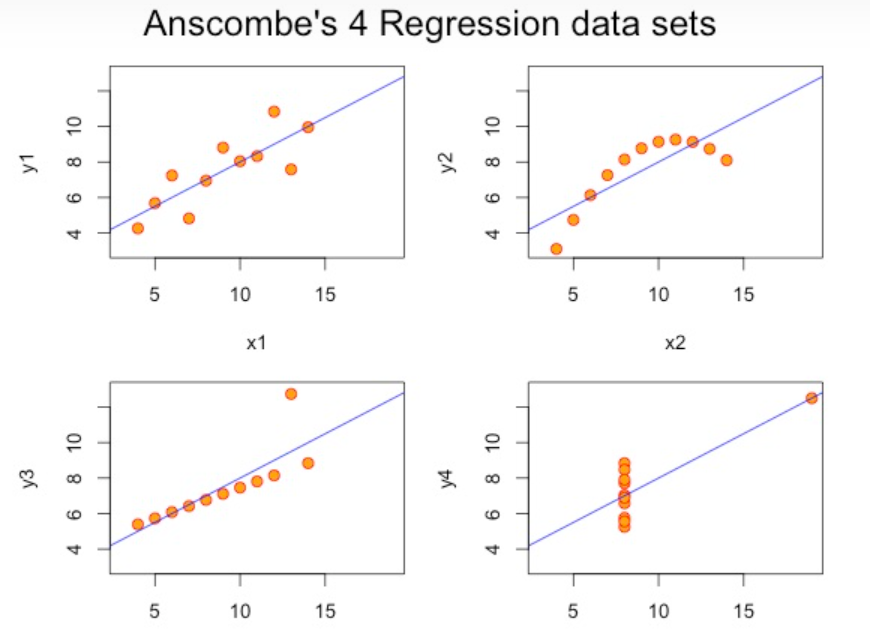
这四组具有相似统计特性但展现不同分布形态的数据集,揭示了单纯依赖数据的统计特性来进行决策可能带来的风险。当对数据集进行分析时,我们不能只看统计指标,这些指标可能掩盖了数据集中的实际模式或趋势。我们需要通过可视化工具进行直观的观察,才能获得全面正确的信息。
总的来说,安斯库姆四重奏向我们展示了数据可能给出的误导。虽然统计分析和方法仍然是我们日常决策中的重要工具,但我们不能只是简单地以数字的形式来理解数据,为了防止落入“数据误区”,我们需要更深入地去理解数据。此外,我们需要充分认识到数据可视化的重要性,并将其运用于我们对数据的理解和解读中。
本文地址:http://sunnao.cn/archives/469
以上内容源自互联网,由运营助手整理汇总,其目的在于收集传播生活技巧,行业技能,本网站不对其真实性、可靠性承担任何法律责任。如发现本站文章存在版权问题,烦请提供版权疑问、侵权链接、联系方式等信息发邮件至candieraddenipc92@gmail.com,我们将及时处理。
相关推荐
-
关于微信电商的一些思考
内容转载自:李明Bright 腾讯又加大力度做电商了。 前几天,一则消息火爆了一下,微信推出微信小商店,提供了给朋友送礼的功能,本质上就是微信要大力度去做电商了。 回想腾讯的电商史…
-
微信小店“送礼物”落后的设计,还是新机会?
内容转载自:努力做产品的小杜 送礼,一直是人与人之间建立和维系关系的重要方式。然而在许多场景中,这种需求因为过于正式或者繁琐的操作而未被满足。微信小店最新上线的“送礼物”功能,试图…
-
数据运营篇 | 数据运营中的权限问题
内容转载自:数据小吏 面向开发的数据权限,在数据管理篇中提到过了,开发的权限主要是在开发团队,开发体系内进行授权设置,可以说还是相对比较固定的,范围相对较小的。 这里主要说面向运营…
-
深入研讨:工具型 App 的定义、架构、痛点及用户体验优化之术
内容转载自:海鲜不设计 我们强调了用户界面的直观性、功能核心的强化、性能优化的重要性、数据安全的保障、用户支持的及时性以及反馈机制的有效性。同时,我们也探讨了如何通过持续迭代、用户…
-
淘宝搜索正在“杀死”淘宝
内容转载自:市象 “淘宝搜索不好用了怎么办”,这个词条在小红书搜索框中显示关联笔记有41万多篇;而“淘宝搜索衣服都是一样的”则有54万多篇。 这些帖子,都指向了同一个事实,淘宝搜索…
-
39、69元陪伴群的赚钱模式分析
内容转载自:十里村 39元、69元等类似的陪伴群到底值不值得加入?有没有坑? 这种付费群的变现模式到底如何?能直接赚到钱吗? 近一年来,类似低价陪伴群模式很多,今天就和大家一起来聊…
-
2025年AI产业发展十大趋势
内容转载自:易观
-
AI时代下的挣钱思路:从消费到创收的转变
内容转载自:小普 当年的时代阵痛是什么?对于许多人来说,意味着突如其来的失业与无助。四十多岁的人,因下岗而陷入困境,既要养家又缺乏一技之长,加上通货膨胀,钱不值钱,生活越来越艰难。…
-
看完抖音电商,你就明白字节AI终局布局
内容转载自:连诗路AI产品 不服不行,抖音电商从圈外到圈内仅用了3年 一、发展历程 2020 年:抖音电商 GMV 近 2000 亿元,还为其他电商平台导流 3000 亿 GMV。…
-
滴滴“臭车”谁之过?
内容转载自:互联网那些事 近日,滴滴因“臭车”问题冲上热搜,相关的媒体报道与话题帖下面,已被大量“感同身受”的网友攻占,堪称互联网奇观! 乘客乘坐体验不满意,提供出行服务的滴滴,成…